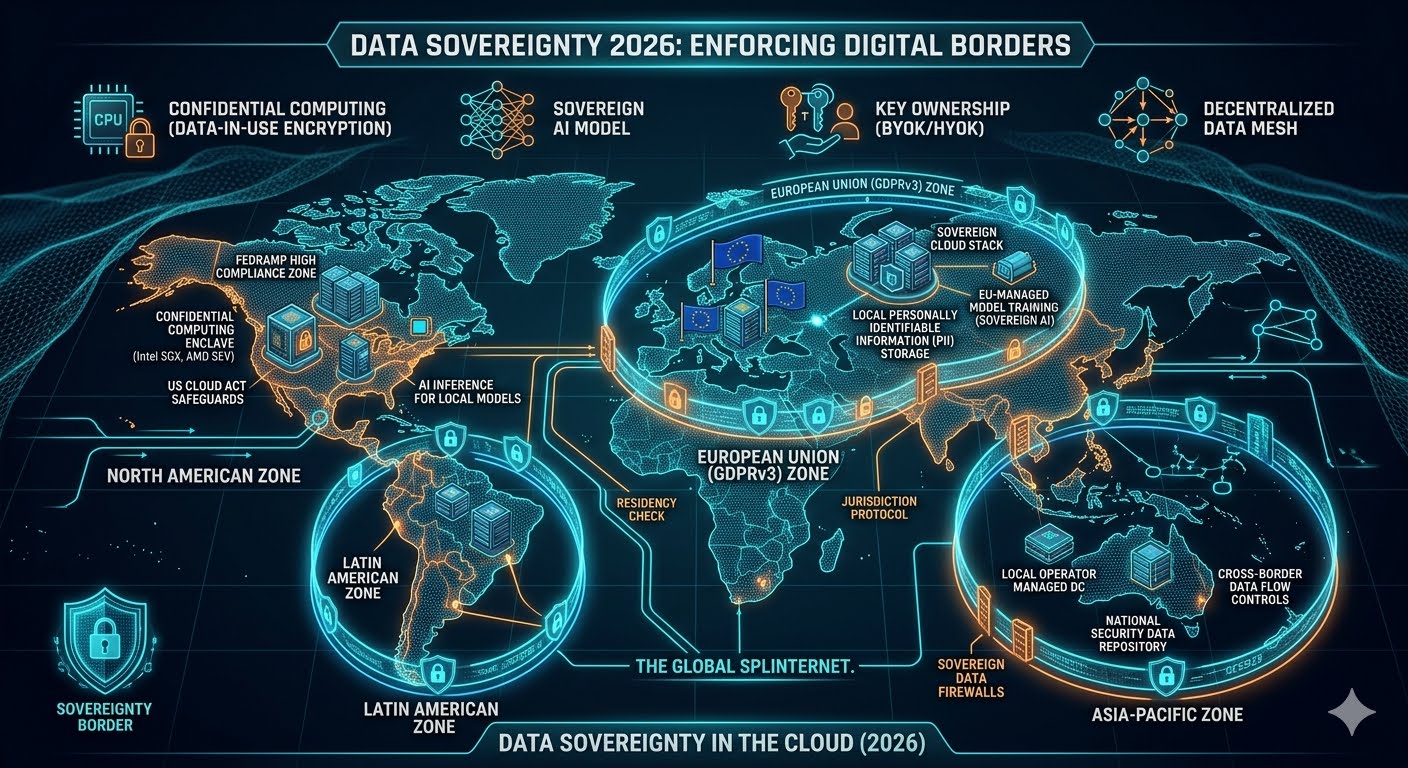
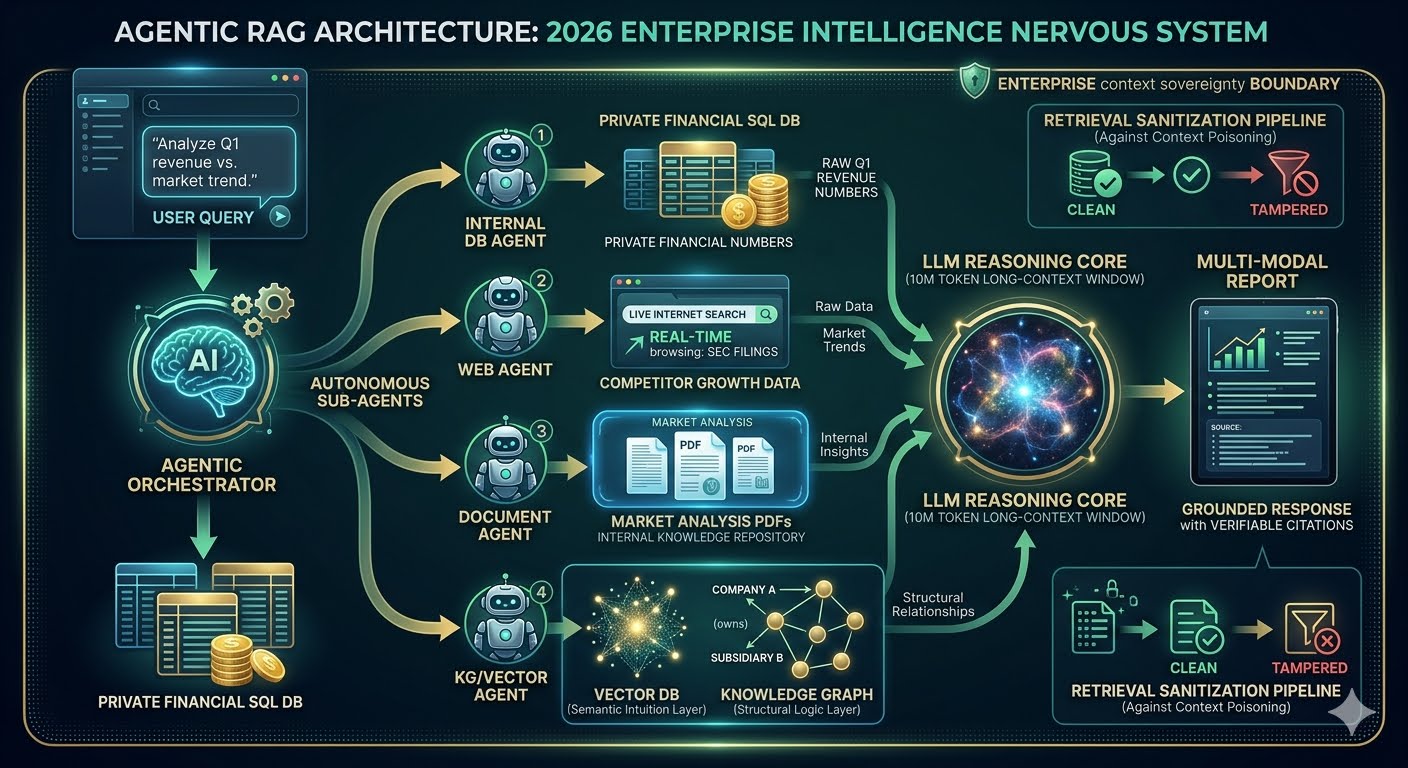
May 13, 2026
8 min read
Introduction to Email Marketing
Email Marketing: Meaning, Types, Process, Benefits and Drawbacks. Email marketing involves sending commercial emails to promote business offerings to existing and potential customers. It is a digital marketing strategy used to engage existing customers and attract new ones. Effective emails have compelling subject lines, personalized content, visuals, clear calls-to-action, and mobile optimization. Campaigns promote updates, offers, events, and content to communicate the brand story. In this article, let’s understand what email marketing is, along with its benefits and drawbacks.What is Email Marketing?Email marketing refers to a digital marketing strategy that uses email to promote business offerings and build relationships with potential or existing customers. The core goal is driving sales revenue through email communications. In email marketing, businesses create customized email campaigns targeted at certain subscriber lists. For example, they may send promotional newsletters or product updates to customers who have purchased before or signed up to receive such emails. The business may also acquire new email list contacts interested in their offerings to expand their subscriber base.Each email campaign involves carefully crafting compelling subject lines and content that speaks to the unique interests and needs of the recipients. Calls-to-action are integrated at key points, guiding the next click. The business works to build trust and nurture ongoing dialogues with its email subscribers over time. The success of email campaigns can be measured by metrics like open rates, click-through rates on links, and conversion rates on desired outcomes like purchases. Email marketing analytics provide insight into optimizing messages and segments for improved results. When used correctly and following best practices, email allows meaningful customer connections that may ultimately lead to sales.Types of Email MarketingMarketers have lots of choices for how to contact customers by email. But some kinds of emails work better than others to help your company, which are as follows:1. Promotional Emails: These are emails focused on promoting special offers, sales, new products, or other commercial announcements to drive purchases and transactions. For example, coupon emails, sale announcement emails, or new product launch emails. They advertise the business's latest deals.2. Newsletters: Newsletters are regular, recurring emails that provide new and updated content like articles, company news, blog summaries, tips, or other useful information to subscribers. Rather than directly promoting products, they aim to build engagement.3. Welcome Emails: Welcome emails are some of the most important emails sent. They are the first email contact when a person signs up and sets the tone of the subscriber relationship. Well-crafted welcome emails introduce the business, highlight subscription benefits, and start subscriber engagement.4. Cart Abandonment Emails: When customers add items to an online shopping cart but don't complete the purchase, cart abandonment emails remind them to return and check out. These transactional emails recover lost sales from shoppers needing an extra prompt to buy.5. Customer Re-engagement Emails: These emails target subscribers who have been inactive for some time by re-engaging with them in an attempt to bring them back for repeat business. Tactics may include sending promo codes, linking to the newest content, or showcasing recently added inventory.6. Onboarding Drip Campaigns: These nurture new subscribers by sending helpful orientation content over their first thirty, sixty, or ninety days. The onboarding series covers topics, like frequently asked questions, product tutorials, sizing guides, user community details, or member benefits to aid in getting started.7. Holiday or Event Emails: These capitalize on major holidays, events, or cultural moments to send relevant communications. For example, Independence Day sales emails, Mother's Day gift ideas emails, or event promotion emails around occasions like music festivals or industry tradeshows. They tie into seasonal moments.8. Ratings and Reviews Emails: These requests satisfy customer reviews or star ratings post-purchase. The feedback allows businesses to monitor satisfaction and improve products. Review emails tend to see high open rates as customers want to share evaluative input.Process of Email Marketing1. Define your Audience: Clearly define your target audience by developing customer personas. Analyze your current customer base to determine key demographics like location, age, income level, gender, occupation, etc. Group them by common interests and behaviors. Get very specific in terms of their unique preferences and needs to shape content that resonates with them.2. Establish your Goals: Decide on the purpose and goals of your email campaigns. Are you aiming to drive traffic, generate leads, increase sales, boost customer engagement, and promote brand awareness? Set specific KPIs related to your objectives, such as email open rates, click-through rates, conversion rates, revenue metrics, or subscribers gained.3. Create your Email List: Build your list through methods like offering opt-in forms on your website, blog, or social channels, capturing leads at in-person events and promotions, and through strategic list acquisition and partnerships. Focus on acquiring email contacts within your target personas. Incentivize subscribers.4. Pick an Email Campaign Type: Select campaign categories that align with audience preferences and business goals. Campaign types include promo emails, content newsletters, win-back offers, post-purchase follow-ups, holiday themes, and more. Map a campaign calendar to your KPIs with campaigns scheduled.5. Make a schedule: Build an email cadence and systematic schedule for how often to send emails to each segment—weekly, monthly, etc. Welcome new subscribers with an onboarding drip series. Leverage automation tools to schedule recurring campaigns like win-back offers. Maintain a sense of exclusivity and anticipation without fatigue.6. Measure your Results: Link the email platform to Google Analytics and add campaign UTM tracking to monitor performance. See what emails drove the most website traffic, subscriber growth, and sales to double down on those while reworking laggards.Benefits of Email Marketing1. Boosted Brand Awareness: Regularly connecting with subscribers through value-driven email campaigns is a proven way to grow meaningful awareness of your brand, offerings, and what sets you apart. Emails that resonate with audiences in a cluttered inbox successfully gain mindshare.2. Cost-Effective Reach: Email is considered an extremely cost-effective marketing channel, often with higher ROI than traditional print or direct mail campaigns. When using email service provider tools, there is very little incremental spending associated with adding more contacts and limited variable costs involved in scaling campaigns.3. Driving Website Traffic: Calls-to-action within email campaigns can effectively direct engaged subscribers to targeted pages on your website or online store. Things like promotional offers, gated content previews, and newsletter highlights convert existing awareness into tangible website visits.4. Lead Generation: Email often sits at the top of the purchase funnel, moving subscribers from awareness into consideration. Asking for a lead-generating action within emails, such as downloading an educational whitepaper or eBook, subscribing to a service trial, registering for a demo, etc., can capture key contact information on hot prospects.5. Enhanced Customer Retention: Ongoing email nurturing beyond the initial sale or sign-up helps retain customers longer. Transactional and promotional emails focused squarely on existing purchasers or loyal members build satisfaction and brand affinity, improving customer lifetime value.6. Sales Growth: Calls-to-action that directly elicit desired conversion events—be it a purchase, account sign-up, or service enrollment—directly generate incremental revenue and pipeline velocity. Of all marketing channels, properly executed email marketing fuels some of the highest customer conversion rates over time.Drawbacks of Email Marketing1. Reaching Inboxes is Hard: With so many emails sent, it can be difficult to have your emails make it into subscriber inboxes instead of getting marked as spam or promotions. Standing out will be a challenge.2. Audience Burnout: If you send too many emails or emails that are not relevant or valuable, subscribers will disengage, open fewer emails, and may even unsubscribe from your list altogether. Preventing this requires continual optimization.3. Time-Consuming to Create: Designing great-looking email templates with compelling content takes extensive time and creative effort. For best results, dedicated staff may be needed, which is an added expense.4. Advanced Analytics requires Work: While email providers offer basic reporting, integrating deeper web and customer analytics requires manually implementing additional tracking tools that may be outside of their core capabilities.5. Reliance on Tech Platforms: Executing email campaigns relies on third-party email service providers. If their deliverability or functionality faces technical issues, your email reliability may suffer through no direct fault of your own.ConclusionEmail marketing can be super helpful for connecting with customers and growing a business when done right. With the perfect foundation built on customer needs, creativity, and constantly optimizing based on data, an email marketing program can be a game-changer. By understanding the dynamics and employing best practices, businesses can leverage the strengths of email marketing while mitigating its drawbacks. Ultimately, a well-executed email strategy will have the potential to promote meaningful connections, drive sales, and fortify brand loyalty.